阅读时间:1 分钟
0 字
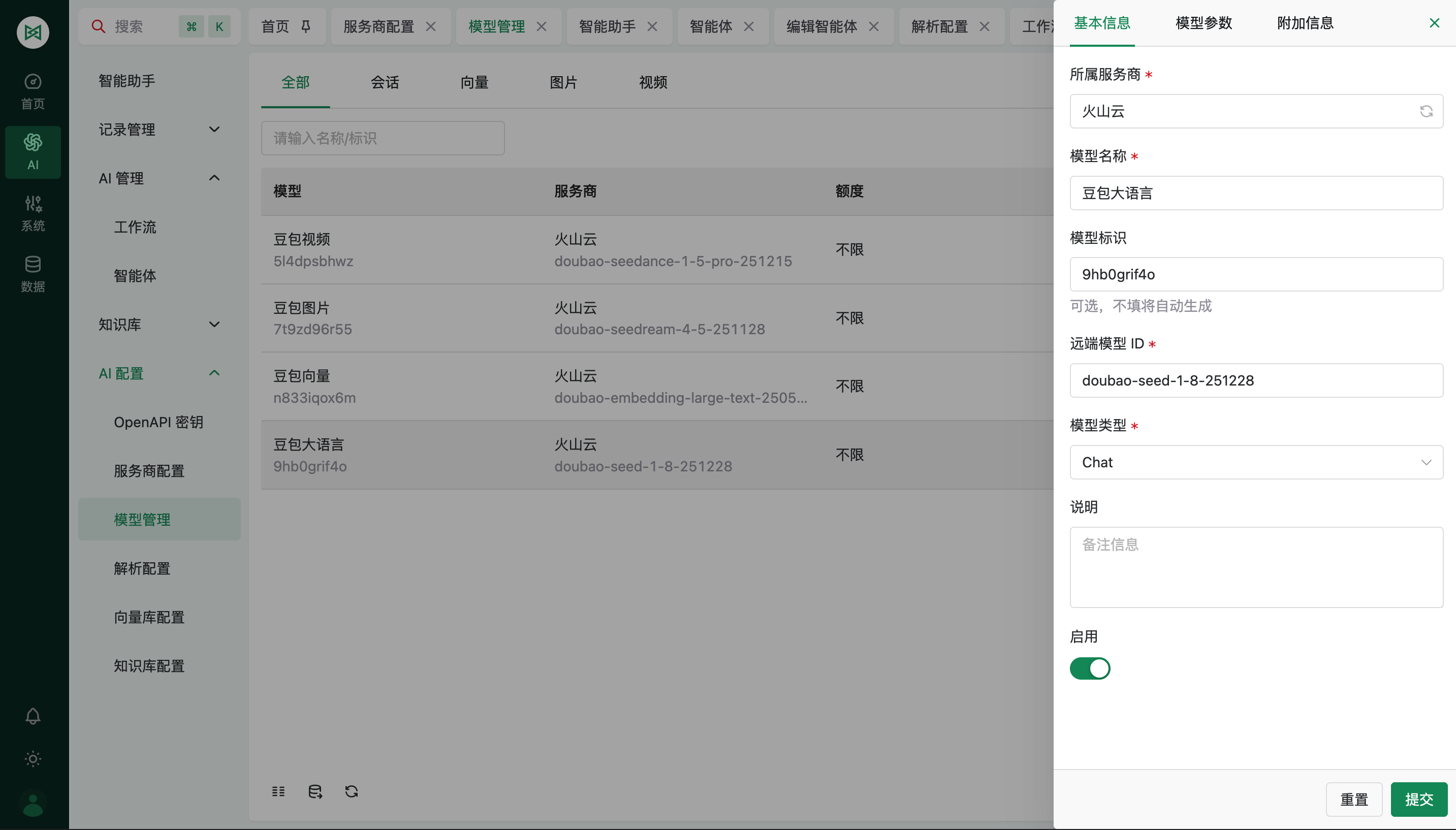
模型配置
模型配置是服务商下的第二层。服务商决定“连哪家”,模型决定“用哪个”。
先理解 4 种模型类型
对话模型:负责智能体聊天、理解需求、组织回答Embedding 模型:负责知识库向量化图片模型:负责图片生成视频模型:负责视频生成
第一次推荐怎么配
建议按这个顺序:
- 先配一个
对话模型 - 如果要做知识库,再补一个
Embedding 模型 - 如果要做图片,再补一个
图片模型 - 如果要做视频,再补一个
视频模型
模型 ID 怎么获取
这里说的“模型 ID”,本质上就是服务商要求你填写的远端模型标识。
不同平台叫法可能不同,例如:
- 模型名称
- Model
- Model ID
- 接入点 ID
- Deployment 名称
最简单的判断方法就是:
去看服务商官方文档里的请求示例,
model字段填的是什么,你这里通常就填什么。
以火山方舟为例:
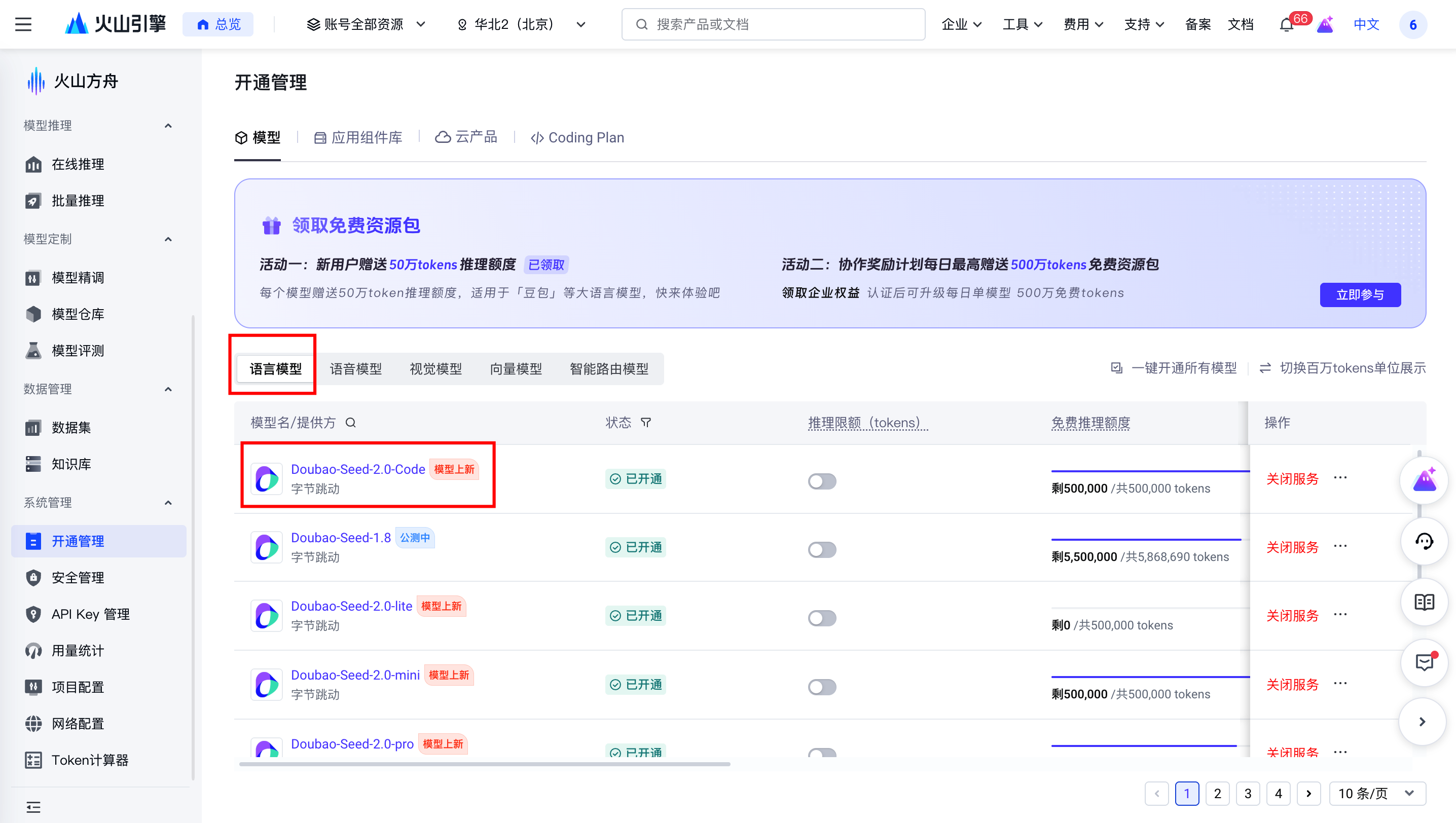
进入模型详情后,可以直接复制模型 ID:
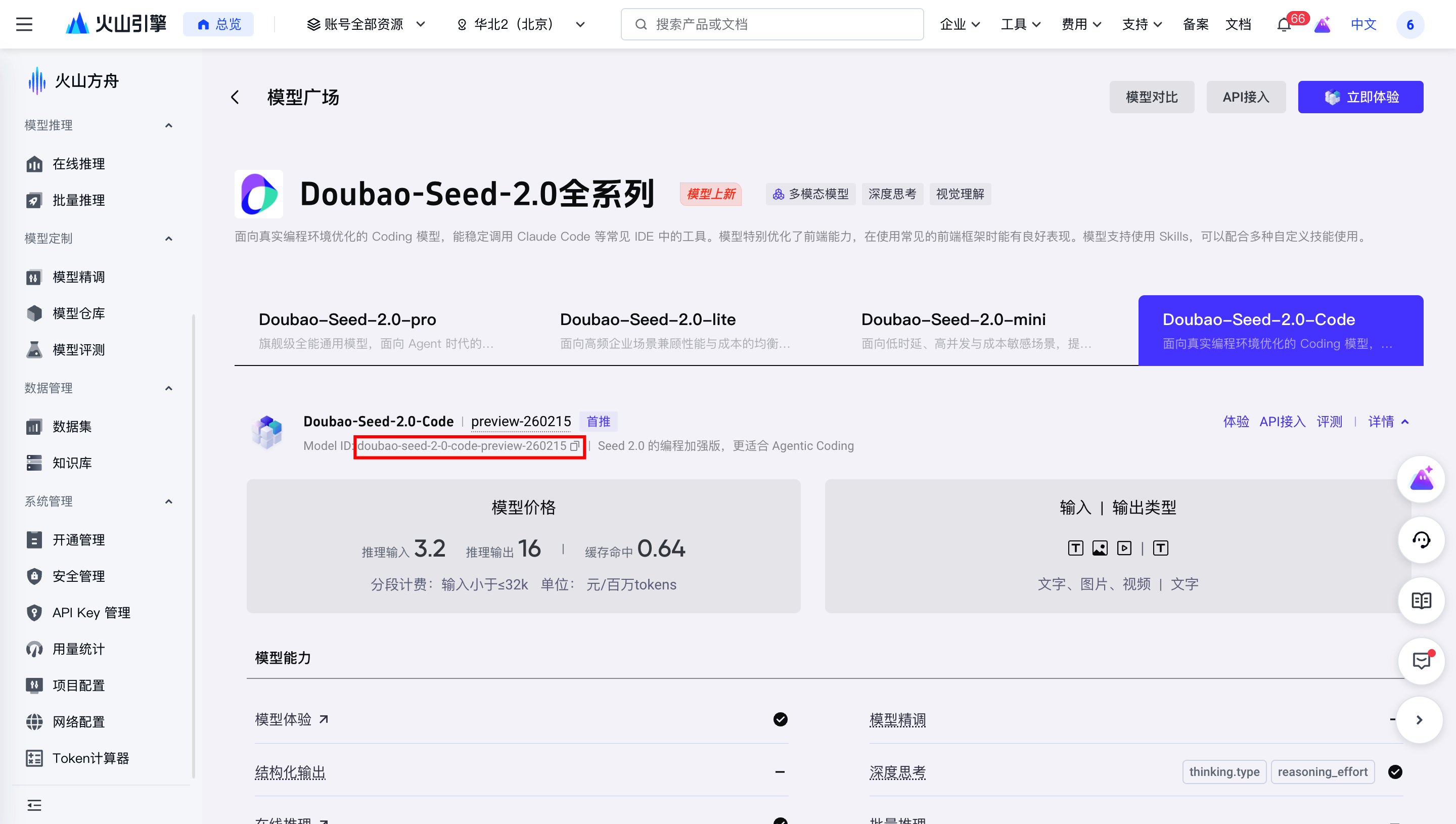
表单里先重点看哪些
如果你是第一次配置,先只关注这些:
服务商模型名称模型 ID模型类型是否启用
其它高级参数,等跑通后再补。
不同模型类型,各自重点看什么
对话模型
先重点看:
- 服务商
- 模型名称
- 模型 ID
- 附件支持
Embedding 模型
先重点看:
- 服务商
- 模型名称
- 模型 ID
- 向量维度
- 批量大小
图片模型
先重点看:
- 服务商
- 模型名称
- 模型 ID
- 媒体存储驱动
- 调试日志
视频模型
先重点看:
- 服务商
- 模型名称
- 模型 ID
- 媒体存储驱动
- 视频压缩设置
- 视频能力参数
Embedding 模型的“维度”怎么理解
如果你配置的是 Embedding 模型,通常会看到一个参数:
向量维度
你可以把它理解成:
这个模型把文本转换成向量后,每条向量有多长。
最重要的一点是:
向量模型维度,最好和向量库维度保持一致。
维度一定要自己填吗
不一定。
建议按这个顺序判断:
- 先看模型官方文档有没有明确维度
- 有明确值就按文档填
- 没有明确值就先留空
- 再去看向量库是否要求单独填维度
不同供应商下怎么处理
OpenAI Compatible:优先看平台文档,没要求就先留空DeepSeek:优先看官方文档,没明确值先留空再测试Ark:优先看模型详情或官方文档里的说明BigModel:文档有明确维度时直接照填
聊天模型里的附件支持怎么理解
聊天模型里有一组“附件能力”,主要决定:
- 是否支持
图片 - 是否支持
文件 - 是否支持
音频 - 是否支持
视频
最常见的 3 种策略:
模型支持:直接交给模型处理本地解析:先在本地解析,再把结果交给模型关闭:不支持这一类附件
文件、解析、存储之间是什么关系
这里最容易混淆,建议直接这样记:
模型:决定能不能接附件解析配置:决定图片 / PDF 怎么识别文字存储配置:决定文件和媒体保存到哪里
它们是协作关系,不是同一个配置对象。
文件接口能力需要手工选吗
不需要。
当前系统会按服务商协议自动识别文件接口能力,不需要手工选文件驱动。
图片 / 视频模型额外要注意什么
图片模型
重点是:
- 选对图片模型
- 确认媒体存储驱动
- 生成数量和尺寸先用默认值
视频模型
重点是:
- 选对视频模型
- 先保持默认压缩参数
- 先用默认轮询和超时设置
如果你只是第一次测试,视频压缩、帧率、码率这些参数都建议先不要调。
小白第一次最容易踩坑的地方
- 只配了图片 / 视频模型,没有配对话模型
- 想做知识库,但没有配 Embedding 模型
- 把模型、解析配置、存储配置混在一起理解